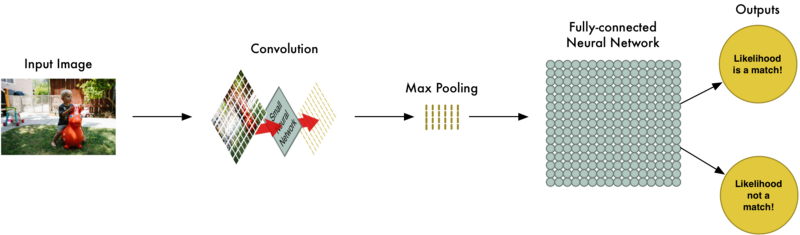
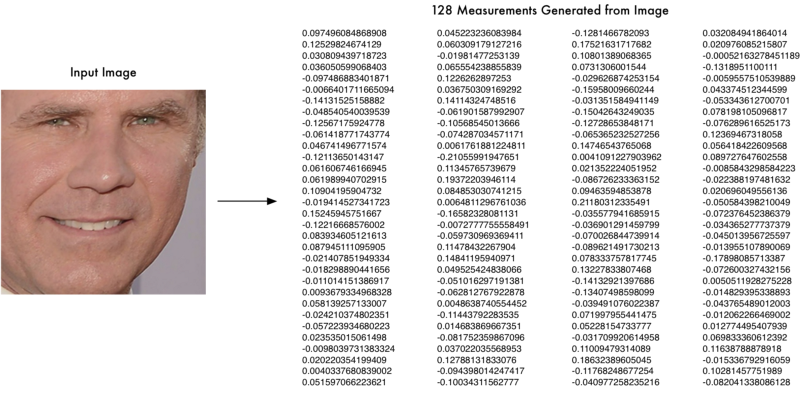Computer Face Recognition
Pixel
The Bottom-up Stimulus for Computers in Face Recognition
Digital images are comprised of tiny amounts of information.
The pixel is the unit of measure for a digital image.
One pixel represents a single color.
Colors can be represented in hex, RGB, gray-scale intensity and other identification schemes.
Example representation schemes (RGB):
| Base | Red | Green | Blue |
|---|---|---|---|
| Decimal | 255 | 0 | 0 |
| Octal (8) | 377 | 0 | 0 |
| Hex (16) | FF | 00 | 00 |
| Binary | 1111 1111 | 0000 0000 | 0000 0000 |
Pixels are identified by their location within the coordinate grid.
Pixels are assembled in a grid system. Each one has coordinates. Each pixel is specified by its position within the grid system as identified by (x-axis, y-axis) using integers.
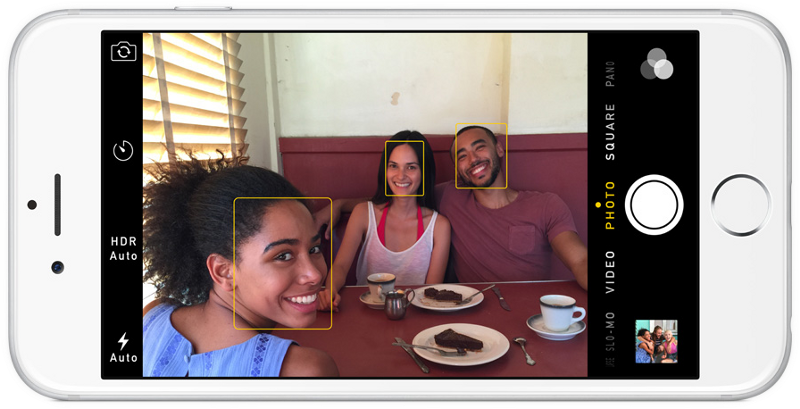
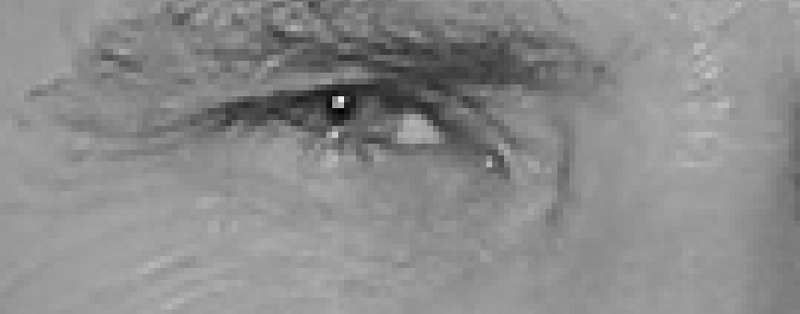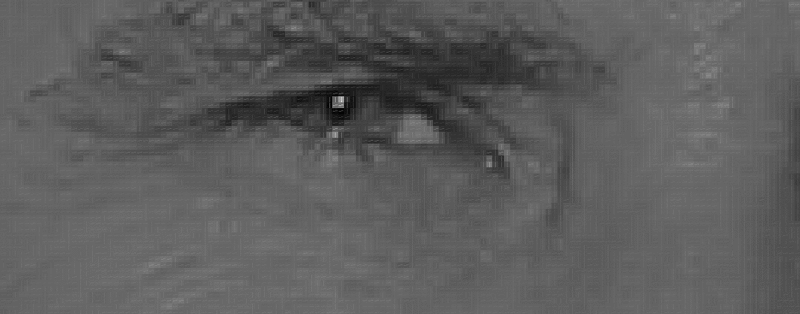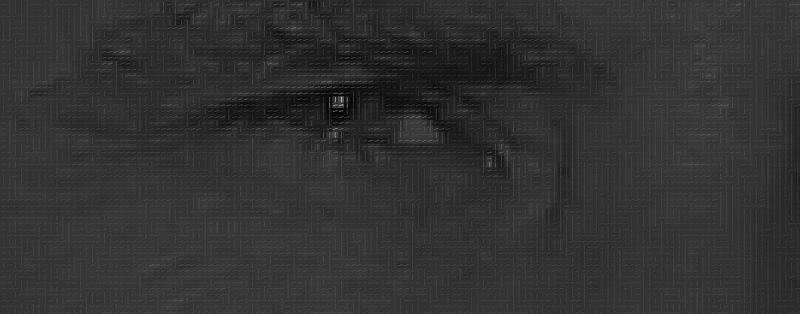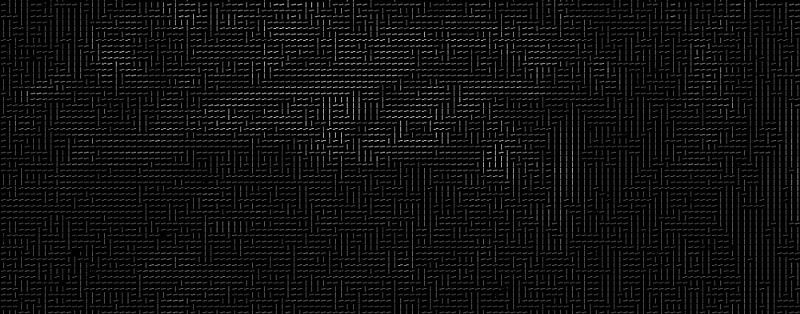

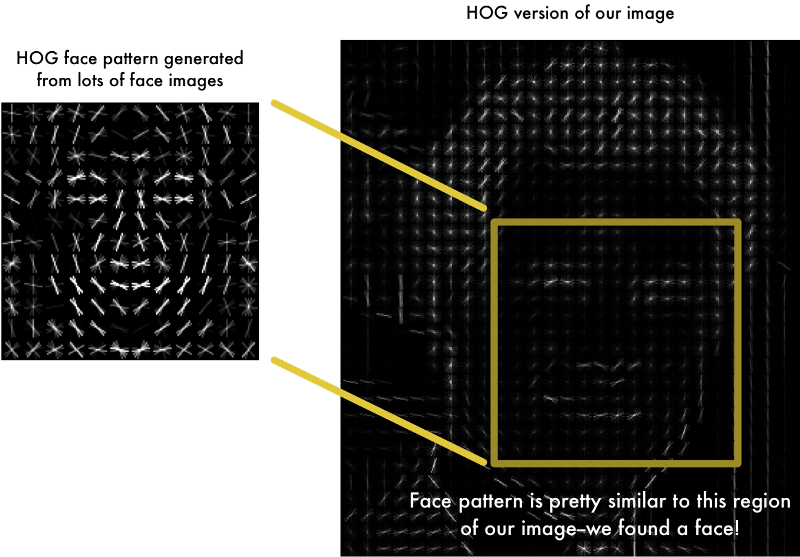

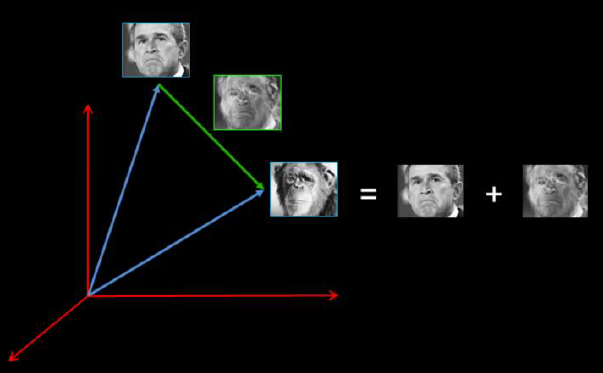
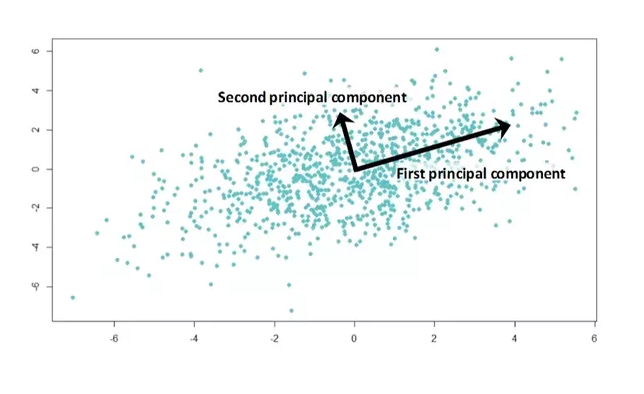


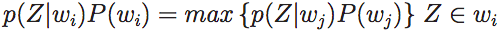 where wi are the face classes and Z an image in a reduced PCA space.
where wi are the face classes and Z an image in a reduced PCA space.